
内田樹さんの記事「ネット上の発言の劣化について」を拝読しました。
現在のネットはJUNETの頃のように学者の方々などだけが利用しているわけではないので、その当時に比べて平均的なテキストのクオリティが劣化したかといえば、その通りだとは思います。
しかし私は、この現象は「劣化」ではなく、ツイッターをはじめとするソーシャルメディアなどで、「世界のあるがままの実態」が見えて来ているということではないかと考えています。
例えれば、今まで「きれいだなー」と思って見ていた花壇の石を裏返してみたら、ちっちゃな虫達がゾワワワワと存在した、みたいな。さらに脇のドブの水を顕微鏡で見てみると、見た事もないような微生物がたくさんいました、みたいな。
そういう、ちっちゃな虫や微生物は、観察することで急に発生したわけではなく、今までもちゃんと存在していたわけです。それと同様に、ネットでの妬みやひがみなどを含んだネガティブな発言も、今まで存在すらしなかったというわけではなく、多くの人々の会話や頭の中にちゃんと存在しており、ただ見る方法が無かっただけのものではないかと思います。
「すべてを見渡す神の視点」といったものが仮に存在するとしたら、かねてからそういう光景が見えていたはずであります。
我々には美女に見える人でも、神はその腸の中にあるウ○コまでが見通せるのであります。すべてが見えてしまう神というのは、つくづく大変だろうなあ、と思います。
エヴァンゲリオン最終2話のように、人を分つ壁(A.T.フィールド)が無くなり、他人の「本当の姿」が見えてしまうというのは、普通の人間には耐えられないことなのかも知れません。
私は最近、まったく逆方向に見える体験もしました。
以前から、自分の所有する数千冊の本をちょっとずつスキャンしてpdfファイルにしてきておりまして、今まで本棚まで(数歩ですが)歩いて「どこにあったかなー」とあちこち探さないといけなかった本が、パソコンの前に座ったままで瞬時に手元で検索できるようになりました。
しかし、分厚い専門書などを全文OCR化するのは非常に時間がかかるので、タイトルや著者名をファイル名に入れたり、一部目次や索引などだけをOCR化することにとどめておりました。
(注:OCRとは、本のページの画像データに加えて、その文章をテキストデータに変換することです。pdfファイルでは本の画像データに加えて、そのテキストデータが検索できるようになります。)
しかし先日、思い切って数百冊分の蔵書をOCR化してみましたところ、これはすごい!、です。
たとえば下記は、「カオス」という単語で、私のMac内にあるファイルを検索してみたものです。
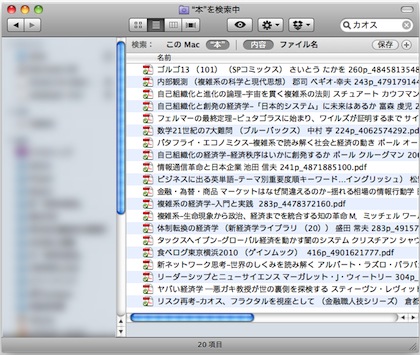
すべての蔵書の中から、タイトルのみならず、本文中に「カオス」の文字を含むものまでが瞬時に検索できるようになったわけです。
この中から、例えば、一番上にある「ゴルゴ13 101巻」のファイルを開いて、さらに検索すると、作品の該当部分がこれまた瞬時に表示されるわけであります。

日本の住宅事情のせいで、重要度の低そうなものは本棚の後ろの列に並んでいたり、押し入れや物置にしまわれていたりで、そういう本があるかどうかすら忘れているケースもあるかと思います。
見やすいところに背表紙が並んでいる本でも、表紙を貫いて中のテキストを透視できるわけではありません。
しかし、本がデータ化すると、それができてしまうんですね。
もちろん、OCRは誤認識もあるので、現在はまだすべての情報の完全な検索は期待できません。
しかし、「すべての本が電子書籍化した未来」というのは、単に本棚のスペースが節約出来るとか、本のハウスダストでくしゃみが出るのが防げる、といったことだけではなく、いろんな人が書いた何百の本棚分もの知や情報が、中身まで瞬時に透視できる世界なのだ、ということではないかと思います。
「発言の劣化」と「膨大な知へのアクセス」は、正反対のものに見えるかも知れませんが、両方とも「世界のあるがままの姿」が徐々に見えてきているという現象を、違う側面から見ただけのことではないかと思います。
また、「観測出来る」ということが、実態に何も影響を与えないかというと、そうではないはずです。
「あるがままの姿」を体験する人類や社会が、今後数十年の間に、どう「変化」していくのか。
非常に興味深いです。
ご参考:「ビジネスマンのための書籍スキャン入門ー既に始まっている電子出版」
(ではまた。)
[PR]
メールマガジン週刊isologue(毎週月曜日発行840円/月):
「note」でのお申し込みはこちらから。